
Qwen2.5
发表时间:2025年03月28日浏览量:
起源:通义千问Qwen 明天,咱们宣布了Qwen2.5-Omni,Qwen 模子家属中新一代端到端多模态旗舰模子。该模子专为全方位多模态感知计划,可能无缝处置文本、图像、音频跟视频等多种输入情势,并经由过程及时流式呼应同时天生文本与天然语音分解输出。 该模子现已在 Hugging Face、ModelScope、DashScope 跟 GitHub上开源开放,你能够经由过程咱们的Demo休会互动功效,或是经由过程Qwen Chat 直接发动语音或视频谈天,沉迷式休会全新的 Qwen2.5-Omni 模子强盛PG麻将胡了(试玩游戏)官方网站机能。 重要特色万能翻新架构:咱们提出了一种全新的Thinker-Talker架构,这是一种端到真个多模态模子,旨在支撑文本/图像/音频/视频的跨模态懂得,同时以流式方法天生文本跟天然语音呼应。咱们提出了一种新的地位编码技巧,称为TMRoPE(Time-aligned Multimodal RoPE)沙巴体育唯一官方网站,经由过程时光轴对齐实现视频与音频输入的精准同步。天然流利的语音天生:在语音天生的天然性跟稳固性方面超出了很多现有的流式跟非流式替换计划。全模态机能上风:在等同范围的单模态模子停止基准测试时,表示出出色的机能。Qwen2.5-Omni在音频才能上优于相似巨细的Qwen2-Audio,并与Qwen2.5-VL-7B坚持等同程度。出色的端到端语音指令追随才能:Qwen2.5-Omni在端到端语音指令追随方面表示出与文本输入处置相媲美的后果,在MMLU通用常识懂得跟GSM8K数学推理等基准测试中表示优良。 模子架构 Qwen2.5-Omni采取Thinker-Talker双核架构。Thinker 模块犹如年夜脑,担任处置文本、音频、视频等多模态输入,天生高层语义表征及对应文本内容;Talker 模块则相似发声器官,以流式方法接受 Thinker及时输出的语义表征与文本,流利分解团圆语音单位。Thinker 基于 Transformer 解码器架构,融会音频/图像编码器停止特点提取;Talker则采取双轨自回沙巴体育网站归 Transformer 解码器计划,在练习跟推理进程中直接接受来自 Thinker 的高维表征,并共享全体汗青高低文信息,构成端到真个同一模子架构。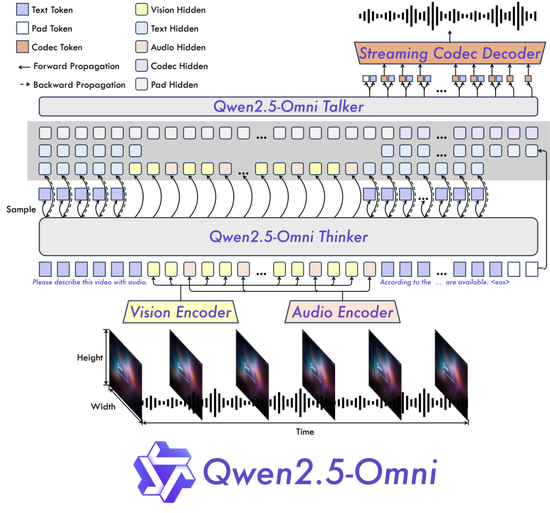 模子架构图 模子机能 Qwen2.5-Omni在包含图像,音频,音视频等种种模态下的表示都优于相似巨细的单模态模子以及关闭源模子,比方Qwen2.5-VL-7B、Qwen2-Audio跟Gemini-1.5-pro。 在多模态义务OmniBench,Qwen2.5-Omni到达了SOTA的表示。别的,在单模态义务中,Qwen2.5-Omni在多个范畴中表示优良,包含语音辨认(Common Voice)、翻译(CoVoST2)、音频懂得(MMAU)、图像推理(MMMU、MMStar)、视频懂得(MVBench)以及语音天生(Seed-tts-eval跟客观天然听感)。
模子架构图 模子机能 Qwen2.5-Omni在包含图像,音频,音视频等种种模态下的表示都优于相似巨细的单模态模子以及关闭源模子,比方Qwen2.5-VL-7B、Qwen2-Audio跟Gemini-1.5-pro。 在多模态义务OmniBench,Qwen2.5-Omni到达了SOTA的表示。别的,在单模态义务中,Qwen2.5-Omni在多个范畴中表示优良,包含语音辨认(Common Voice)、翻译(CoVoST2)、音频懂得(MMAU)、图像推理(MMMU、MMStar)、视频懂得(MVBench)以及语音天生(Seed-tts-eval跟客观天然听感)。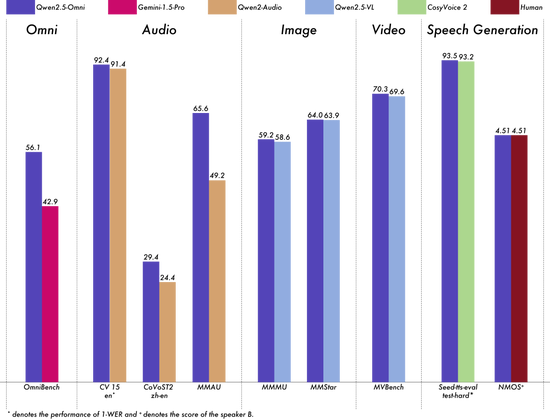 模子机能图 下一步 咱们等待听到你的反应,并看到你应用 Qwen2.5-Omni 开辟的翻新利用。在未几的未来,咱们将出力加强模子对语音指令的遵守才能,并晋升音视频协同懂得才能。更值得等待的是,咱们将连续拓展多模态才能界限,以开展成为一个片面的通用模子! 休会方法 新浪财经大众号 24小时转动播报最新的财经资讯跟视频,更多粉丝福利扫描二维码存眷(sinafinance)
模子机能图 下一步 咱们等待听到你的反应,并看到你应用 Qwen2.5-Omni 开辟的翻新利用。在未几的未来,咱们将出力加强模子对语音指令的遵守才能,并晋升音视频协同懂得才能。更值得等待的是,咱们将连续拓展多模态才能界限,以开展成为一个片面的通用模子! 休会方法 新浪财经大众号 24小时转动播报最新的财经资讯跟视频,更多粉丝福利扫描二维码存眷(sinafinance)
模子架构图 模子机能 Qwen2.5-Omni在包含图像,音频,音视频等种种模态下的表示都优于相似巨细的单模态模子以及关闭源模子,比方Qwen2.5-VL-7B、Qwen2-Audio跟Gemini-1.5-pro。 在多模态义务OmniBench,Qwen2.5-Omni到达了SOTA的表示。别的,在单模态义务中,Qwen2.5-Omni在多个范畴中表示优良,包含语音辨认(Common Voice)、翻译(CoVoST2)、音频懂得(MMAU)、图像推理(MMMU、MMStar)、视频懂得(MVBench)以及语音天生(Seed-tts-eval跟客观天然听感)。 模子机能图 下一步 咱们等待听到你的反应,并看到你应用 Qwen2.5-Omni 开辟的翻新利用。在未几的未来,咱们将出力加强模子对语音指令的遵守才能,并晋升音视频协同懂得才能。更值得等待的是,咱们将连续拓展多模态才能界限,以开展成为一个片面的通用模子! 休会方法 新浪财经大众号 24小时转动播报最新的财经资讯跟视频,更多粉丝福利扫描二维码存眷(sinafinance) 